株式会社チャネルブリッジ
生成AIモデルのトレーニングと評価のための高品質な日本語データの不足に対処するため、設計パートナーや企業の募集を開始しました
米国ニューヨークに本社を構えるAnote, Inc.(CEO:Natan Vidra)は、株式会社チャネルブリッジと連携し、日本語の大規模言語モデル(LLM)の評価と性能向上を目的とした新たな取り組みを開始したことを発表しました。
本日より、日本国内に拠点を置くAI開発企業または研究機関を対象に、限定パイロットプログラムへの参加申請受付を開始します。
このプロジェクトは、Anoteが新たにリリースしたエンドツーエンドのMLOpsプラットフォームを中心に展開され、人間中心型AI開発へのアクセスを誰もが享受できる環境の実現を目指しています。データアノテーションからファインチューニング、推論、評価、統合に至るまで、LLM導入の全プロセスを一貫してサポートします。
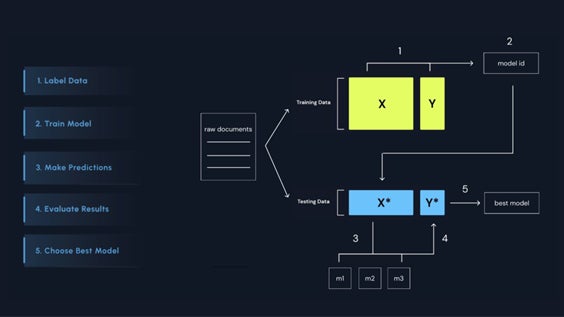
Anoteは、ユーザーのデータに最適な大規模言語モデル(LLM)を構築できるエンドツーエンドのMLOpsプラットフォームです。
Anote上では、GPT、Claude、Llama3、MistralといったゼロショットLLMと、ドメイン固有のトレーニングデータでファインチューニング(教師あり・教師なし・RLHF)されたLLMを比較できる評価フレームワークを提供しています。
また、生の未構造データをLLM対応フォーマットに変換するデータアノテーションインターフェースを備えており、専門家の知見をトレーニングプロセスに組み込むことで、モデル精度を向上させることができます。
エンドユーザーは、最適なLLMを自身のオンプレミス環境にあるプライベートチャットボットに統合したり、ファインチューニング用ソフトウェア開発キット(SDK)と連携して利用することも可能です。
日本語LLMが直面する重要課題への挑戦
現在、多言語対応LLMの学習データは英語が60〜70%を占める一方、日本語はわずか3〜5%に留まっており、この格差が日本語でのAI利用に深刻な性能低下をもたらしています。本プロジェクトはこの課題に取り組み、日本語開発者・研究者に向けて、より優れた日本語AIを構築・検証するためのツールとインフラを提供します。
主な対応課題
日本語トレーニングデータの不足と品質問題
→ 高品質かつ大規模な日本語トレーニングデータセットを生成支援
日本語LLM評価基準の不在
→ 日本初の公開型LLM評価データセット・指標・リーダーボードを導入
ファインチューニング環境へのアクセス制限
→ Anoteプラットフォームを活用し、自社データでカスタムLLMを構築・運用可能
Anoteのユニークな特長
エンドツーエンドMLOps:アノテーション、ファインチューニング(LoRA/QLoRA/RLHF対応)、推論、評価、統合までを一括でサポート
マルチモデル比較:GPT-4o、Claude 3.5、Llama 3、Mistralなどとファインチューニング済みモデルを日本語データで比較
高度な評価フレームワーク:Cosine Similarity、Rouge-L、LLM Eval、Answer Relevance、Faithfulness等でモデル性能を多面的に評価
多様なタスク対応:テキスト分類、固有表現抽出(NER)、全文書型QA、プロンプトQAに対応
即時統合可能なAPI・SDK:最適モデルを業務環境に迅速に統合可能

本技術の核となるのは、最先端のFew-Shot Learning(少数ショット学習)を活用し、わずかなラベル付きサンプルから高精度な予測を行うファインチューニングライブラリです。
LLMをラベル付きデータでファインチューニングするには、教師ありファインチューニングを実行できます。
さらにモデル性能を向上させるためには、教師ありファインチューニングまたはRLHF/RLAIFファインチューニングを、
AnoteのデータアノテーションインターフェースまたはAPIを通じて実施できます。
このプロセスは、以下の4つの主要ステップで構成されています:
アップロード:新しいテキストデータセットを作成
カスタマイズ:分類カテゴリ・抽出エンティティ・質問などを設定
アノテーション:少数のエッジケースにラベル付けすると、LLMが残りを能動学習
ダウンロード:生成されたCSVまたはファインチューニング済みモデルをAPIエンドポイントとしてエクスポート
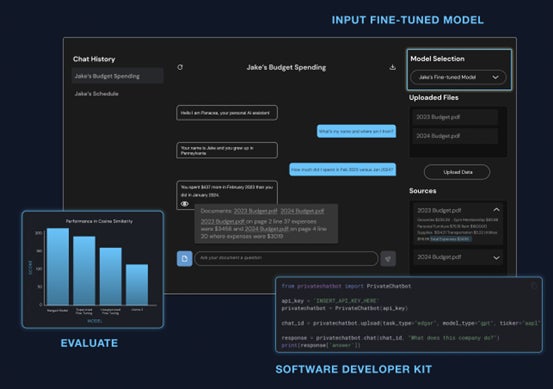
ファインチューニング済みモデルを活用し、正確かつプライベートな企業向けAIアシスタントを構築可能です。
主な手順:
アップロード — 自社のドキュメントをアップロード
チャット — GPT、Claude、Llama2、MistralなどのLLMを使い、ドキュメントに関する質問を実施
評価 — 回答の出典(引用)を提示し、ハルシネーションの影響を低減
評価ダッシュボードでは、ファインチューニング効果をCosine Similarity、Rouge-Lスコア、LLM Eval、Answer Relevance、Faithfulnessなどの指標で確認可能です。
本プロジェクトを通じて、参加パートナーは以下を実現できます:
-
日本語と言語コンテキストに最適化されたモデルの構築
-
ファインチューニングLLMを活用した内部ツールやプロダクト開発
-
日本語NLP向けの初の公開型ベンチマークデータセットへの貢献
-
Anoteリーダーボードや共著研究による成果発信
募集概要
対象:日本国内で生成AIまたはLLM開発に携わる企業、スタートアップ、研究機関
募集数:最大5組織
プロジェクト期間:2025年6月1日~10月1日
応募締切:2025年5月17日
応募方法:下記連絡先までご連絡ください
お問い合わせ・申請先
Anote, Inc.(担当:Natan Vidra -ナタン・ヴィドラ)
Email: nvidra@anote.ai
Web: https://anote.ai/
Anote日本国内パートナー(株式会社チャネルブリッジ)
Email: info@ch-bridge.com